Just about every major database deals with memory in terms of pages. “Page” here refers to a continuous block of memory of fixed size that is typically a multiple of Linux kernel page size (historically, 4096B). Rows can be arranged within a page in various ways.
The granddaddy of all database page layouts is the NSM format, which most traditional RDBMSes use. Rows are appended sequentially to a page. Updates to a row are usually done by marking a tombstoned bit (or setting some snapshot identifier), following by appending the updated row.
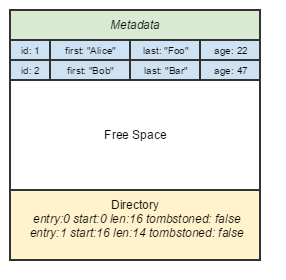
NSM page format.
- Pros: Fastest write performance of all page layouts — simple sequential append to a logical file. Easy to access the whole row and return it. Lots of techniques to index the row itself exist.
- Cons: Not easy to project on variable-length rows. SIMD performance not accessible on columns.
The traditional alternative to NSM is the DSM layout, which is the classical “column-oriented” database page layout. Individual elements within a row are teased out, and are grouped by their own columns.
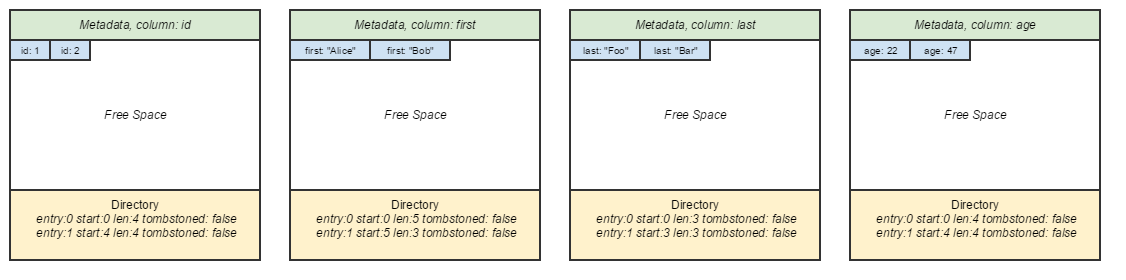
Column-oriented DSM page layout.
It’s my belief that column-oriented databases sound amazing when one first hears of them, but think through them critically, and they’re not as amazing. Their classical advantage is in query performance — just slurp up a bunch of fixed-length elements while reading, maybe even load them to a SIMD register and perform calculations in parallel.
Except that… the overhead in splitting them up, storing them separately, and stitching columns back together is significant, especially when taking consistency in consideration. Whereas a row is the atomic block of consistency in NSM databases, the individual element is the atomic block in column-oriented stores.
The query performance advantage only applies to a narrow set of queries. It is non-trivial to do projections on columns that involve filtering on a separate column. It’s not surprising that HBase, probably the most widely used column-oriented database, advises against creating more than 2-4 “column families” (their terminology for separate groupings of elements). In short, the advantage of DSM is limited to a narrow set of queries that arguably do not see a lot of real world value.
- Pros: Fast theoretical query & calculation performance. Possible improved update I/O performance due to not having to write the whole row on update.
- Cons: Significant overhead in writes and reads of whole rows; consistency will add more overhead to queries due to a lower granularity to track. Best-case query & project scenarios are not necessarily common-case scenarios.
The PAX page layout groups rows by their constituent elements, on the same page.
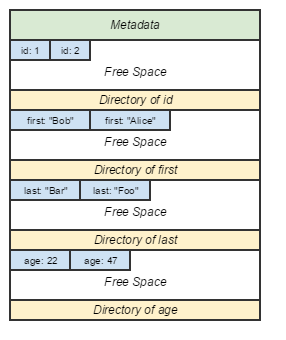
PAX page layout.
- Pros: Eliminates most of the major disadvantages of the DSM model.
- Cons: Challenging implementation. Some disadvantages persist, they just don’t require hopping pages. Real-world performance data lacking.
In addition to the above three formats, an endless variety exist. Fractured mirrors take advantage of replication to combine multiple page layouts and to try and have the best of all worlds. NoSQL databases typically implement some variety of the above, or use their own format. HBase, for instance, records its updates to a WAL and otherwise keeps its rows in a memory cache, and flushes batches to an “immutable” logical file sorted by row identifier.